video-to-sqlite
Inspired by Simon Willison's collection of sqlite tools, I created
a library for extracting information from a video, and storing it in an sqlite database. It's
called video-to-sqlite. You can also install it
via pip install video-to-sqlite.
You can use Simon's very nifty tool Datasette to explore the resulting DB. Let's use this exploration of John Green's powers of discernment with regard to soda brands:
Create the database like so, and begin serving it locally:
video-to-sqlite vlogbrothers.db green.mp4
datasette vlogbrothers.db
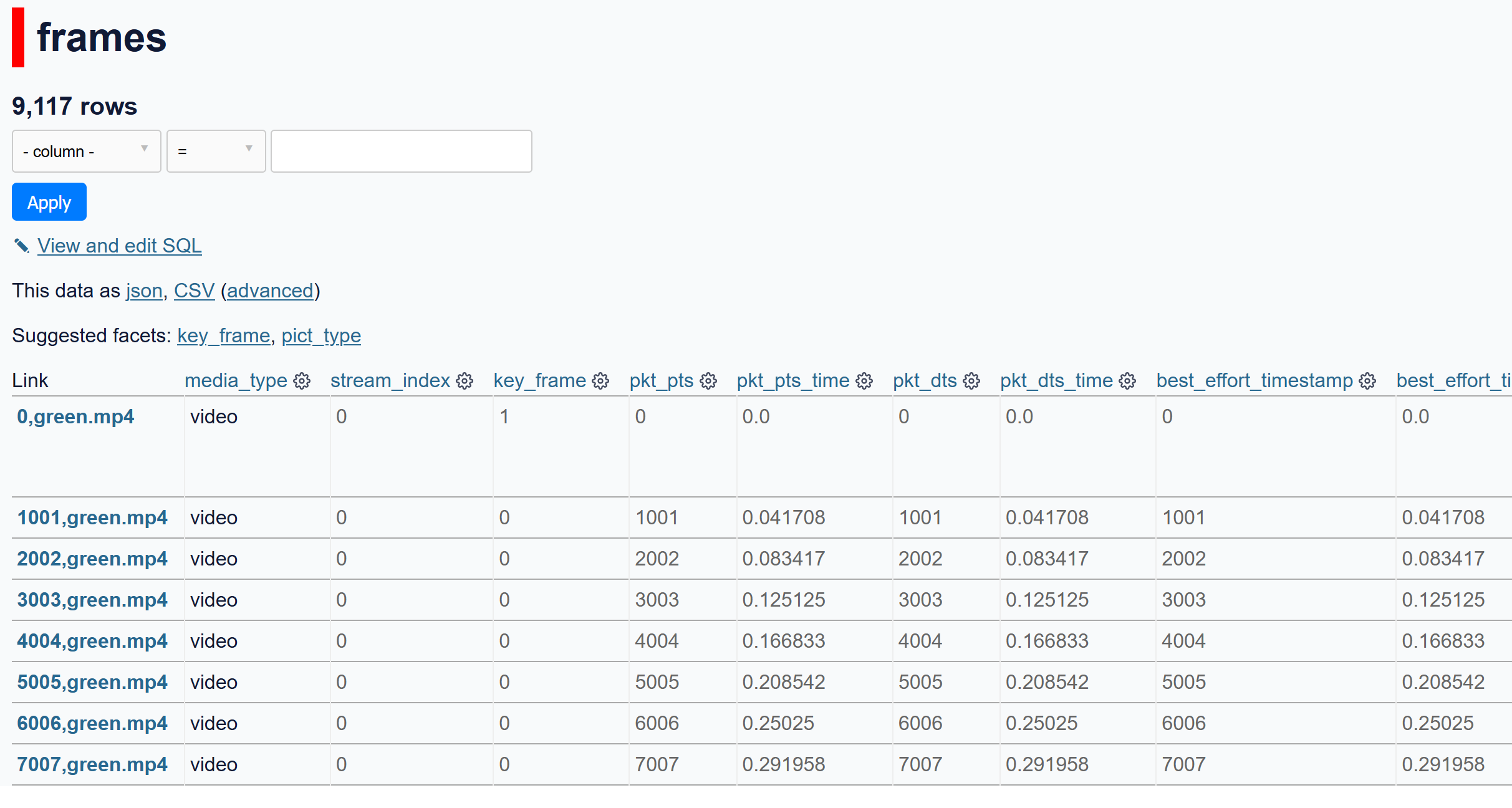
If we visit localhost:8001 in a browser, we can see there's a little over 9,000 frames in
the video, and metadata about each:
We can also run custom sql against the database. For example, counting how many keyframes, predicted frames, and bidirectional predicted frames there are:
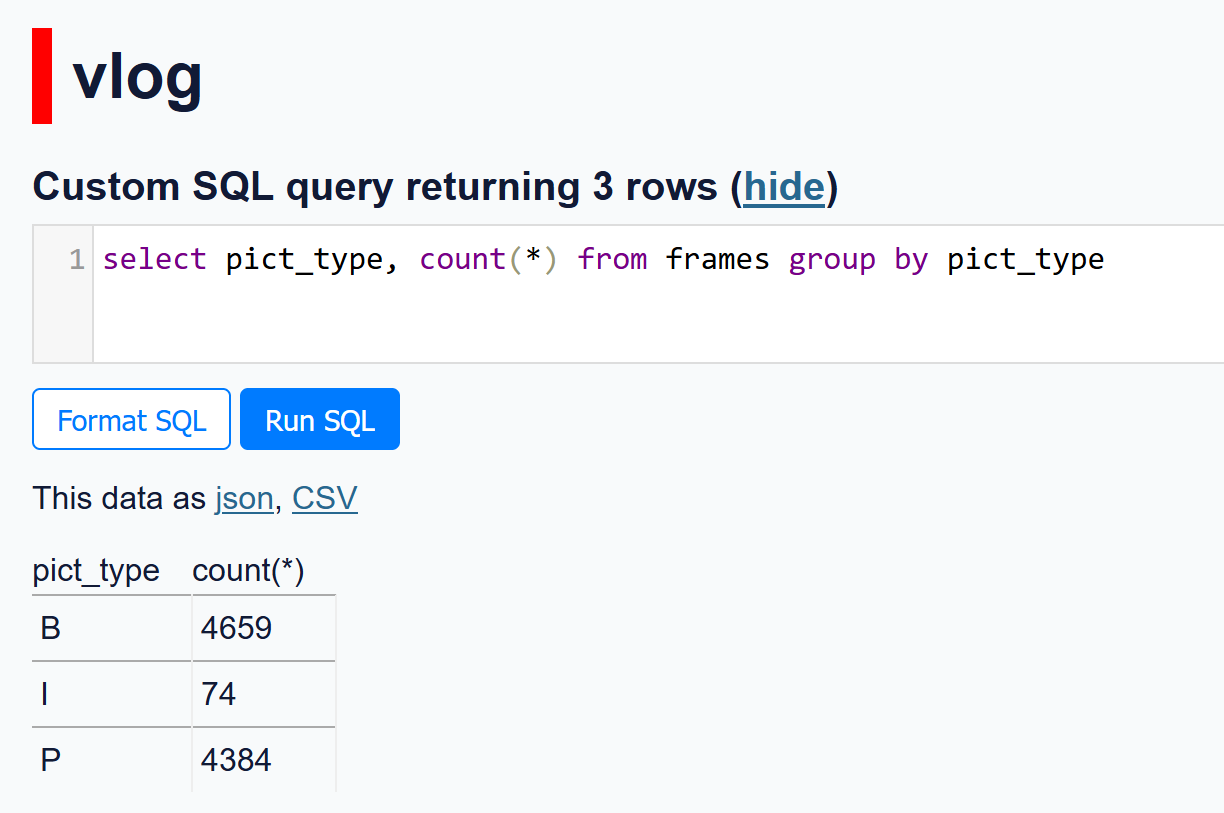
This is already pretty interesting. However, we can do even more with this.
Creating a custom search engine for video contents
video-to-sqlite supports running a custom function against every frame during extraction.
One could use that hook to OCR the frame and store that along with the rest of the metadata,
for example. You might write that something like this:
import video_to_sqlite
def ocr_callback(frame, metadata):
text = ocr(frame)
return {'text': text}
video_to_sqlite.main('vlogbrothers.db', 'green.mp4', prefix=None, callback=ocr_callback)
You would then get a db with those text contents associated with the frame:
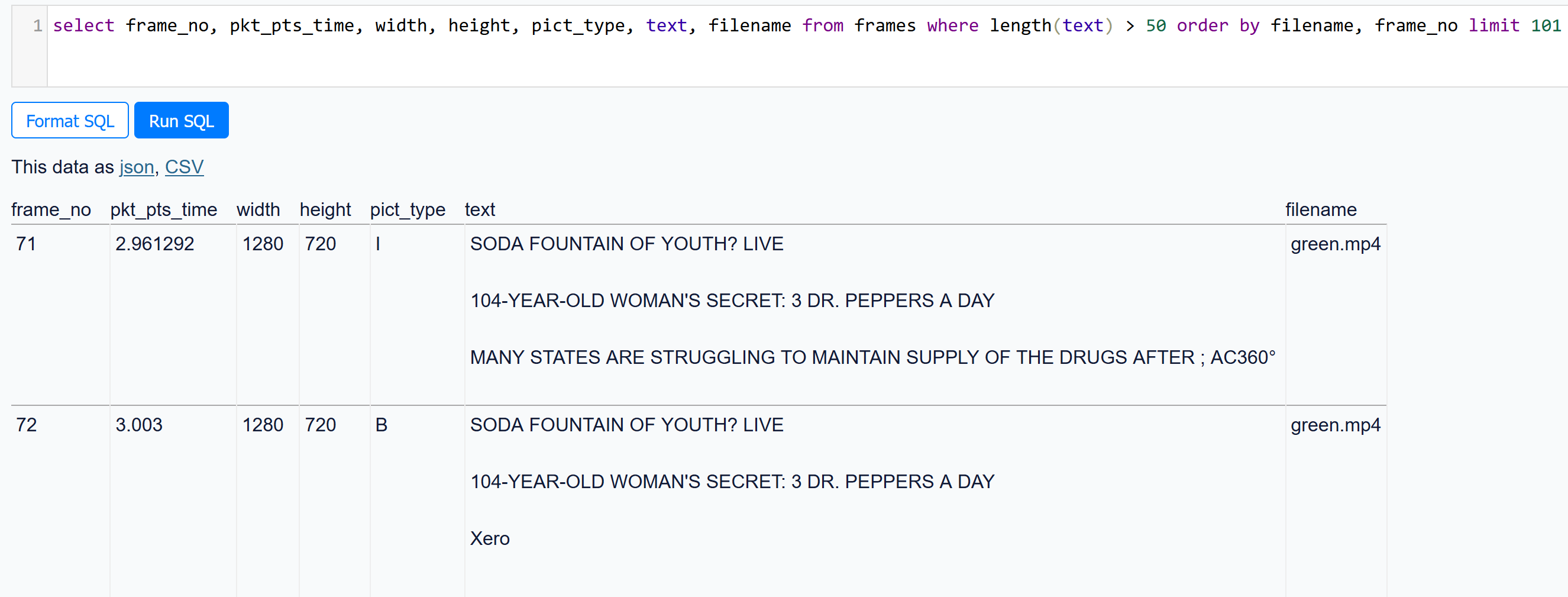
But we can still do one better. Datasette has a plugin called datasette-media.
It lets you serve static files alongside regular datasette responses. For example, viewing images
associated with a URL, like the imageset used to train Stable Diffusion.
I hacked up datasette-media to return individual
frames from a video on request. Combined with datasette, this can show you the frame in
question for each row. You need to specify some config values for datasette, in a file usually
called metadata.json:
{
"plugins": {
"datasette-media": {
"video": {
"sql": "select filename as filepath from frames where filename=:key",
"enable_transform": true
}
}
}
}
Now if you run datasette -m metadata.json vlogbrothers.db you can get something like:
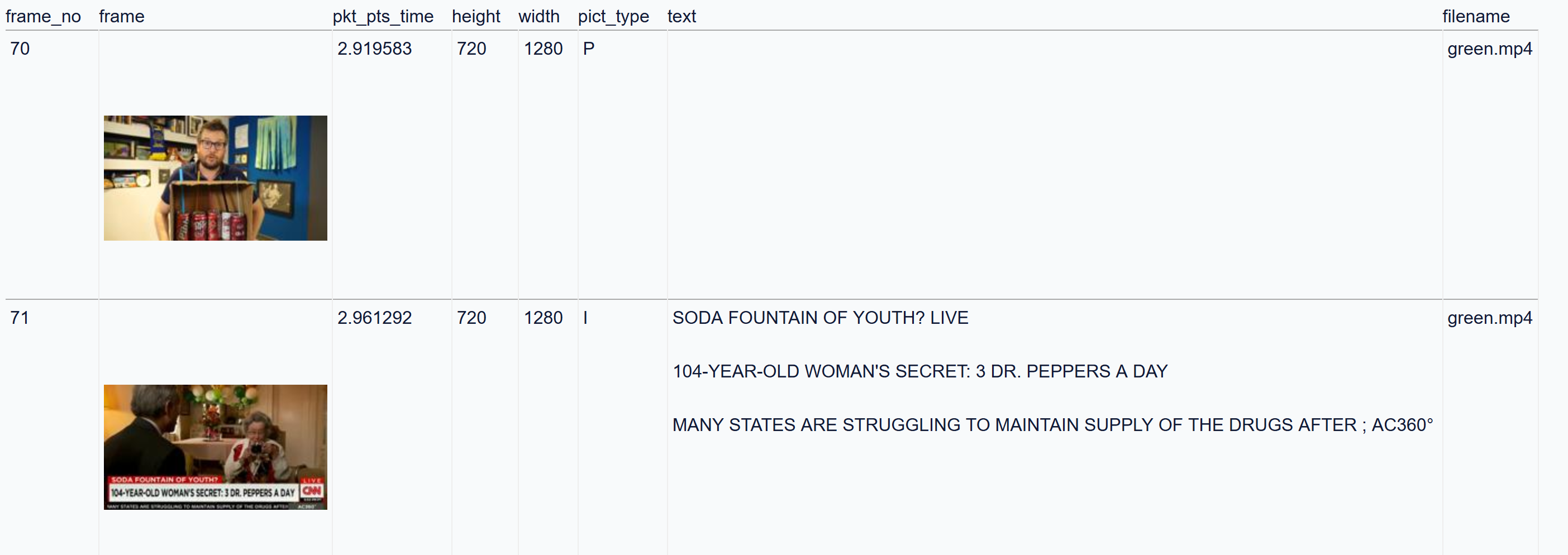
Additionally, datasette also functions as a JSON API. Combining everything, we can create an API to grep video contents and get the corresponding frames:
curl "http://localhost:8001/vlogbrothers.json?_shape=arrayfirst&sql=select+%22http%3A%2F%2Flocalhost%3A8001%2F-%2Fmedia%2Fvideo%2F%22+||+filename+||+%22%3Fframe_no%3D%22+||+frame_no+||+%22%26w%3D200%22+as+frame+from+frames+where+pict_type+%3D+%22I%22+order+by+filename%2C+frame_no+limit+101"
[
"http://localhost:8001/-/media/video/green.mp4?frame_no=0&w=200",
"http://localhost:8001/-/media/video/green.mp4?frame_no=71&w=200",
"http://localhost:8001/-/media/video/green.mp4?frame_no=94&w=200",
"http://localhost:8001/-/media/video/green.mp4?frame_no=188&w=200",
"http://localhost:8001/-/media/video/green.mp4?frame_no=300&w=200",
[...]
Sound useful? Interesting? Let me know if you use it for something cool.
Video from Vlogbrothers used under CC-BY